Duplizierte Inhalte werden von Google in vielen Fällen abgestraft. In unserem Blogbeitrag über Duplicate Content klären wir über Situationen auf, in denen die Dopplung von Inhalten strikt vermieden werden sollte. Dabei informieren wir über Möglichkeiten zur Vermeidung von Duplicate Content.
Zudem erläutern wir als Textagentur, wie gehandelt werden sollte, wenn es zu Duplicate Content kommt. Somit sind die folgenden Informationen für eine hochwertige Suchmaschinenoptimierung (SEO) unerlässlich.
Das Wichtigste in Kürze
- Duplicate Content tritt bei der Dopplung von Inhalten zwischen verschiedenen URLs auf. Nutzen Personen auf ihrer eigenen Website identische oder sehr ähnliche Texte von fremden Websites, dann liegt beispielsweise Duplicate Content vor.
- Ein beliebtes Tool, um Duplicate Content zu finden, ist Siteliner. Bei diesem Tool werden die von Duplicate Content betroffenen Seiten angezeigt, woraufhin sie optimiert werden können.
- Bei der Vermeidung und Beseitigung von Duplicate Content spielen auch technische Aspekte eine Rolle. Canonical-Tags, Noindex-Tags und hreflang-Tags sind wichtige technische Maßnahmen zum korrekten Umgang mit Duplicate Content.
Was ist Duplicate Content?
Als Duplicate Content (Deutsch: doppelter/duplizierter Inhalt) bezeichnet man es, wenn auf verschiedenen URLs identische oder sehr ähnliche Inhalte zu finden sind.
Duplizierte Inhalte sind mit Blick auf die Suchmaschinenoptimierung (SEO) in den meisten Fällen problematisch. Immer dann, wenn Google vermutet, dass Duplicate Content zur Manipulation der Suchergebnisse verwendet wird, drohen Abstrafungen. Entweder wird als Folge der versuchten Manipulation die spezifische Seite mit dem Duplicate Content im Ranking abgestraft oder die Sanktionierung trifft sogar die gesamte Website.
Zudem gibt es bestimmte Bereiche einer Website, in denen sich Textbausteine traditionell doppeln und dies von Google toleriert wird; das ist etwa beim Footer der Fall.
Trotz der Toleranz von Duplicate Content in bestimmten Fällen, sind Website-Betreiber am besten damit beraten, doppelte Inhalte zu vermeiden.
In Anbetracht der Tatsache, dass niemand voraussehen kann, wann Google oder andere Suchmaschinen bestimmte Textbausteine oder ganze Texte als Duplicate Content bewerten, ist die Prävention duplizierter Inhalte eine sehr gute Strategie – zumal Webseiten, die einen möglichst hohen Anteil an Unique Content erhalten, ohnehin die besseren Chancen auf ein hohes Ranking in den Suchmaschinen verzeichnen und in der Gunst der User meist weiter vorn stehen.
Voraussetzungen für das Vorliegen von Duplicate Content
Damit Duplicate Content vorliegt, müssen die Inhalte auf verschiedenen URLs nicht nur identisch oder zumindest sehr ähnlich sein.
Eine weitere Voraussetzung für das Vorliegen von Duplicate Content besteht darin, dass die betreffenden URLs von Google bzw. anderen Suchmaschinen indexiert sind; Suchmaschinen können nämlich nur indexierte Webseiten auffinden und crawlen.
Website-Betreiber nutzen diesen Umstand dazu, um Webseiten mit Duplicate Content auf „noindex“ zu setzen und auf diese Weise Abstrafungen durch Google zu verhindern:
- Durch die technische Anweisung „noindex“ werden die betreffenden Seiten nicht indexiert.
- Trotzdem können Besucher der Website sich über das Menü oder auf anderem Wege zu den nicht indexierten Seiten navigieren und den Content lesen.
- Bei „noindex“ handelt es sich also um eine Maßnahme, die die nicht indexierten Seiten lediglich aus dem Crawling durch Suchmaschinen und somit aus den Suchergebnissen ausschließt.
Bei der Definition von Duplicate Content verbleibt die Gretchenfrage, wann man Textbausteine oder ganze Texte überhaupt als „identisch“ oder „sehr ähnlich“ bezeichnen kann. Zumindest die Definition von „identisch“ ist einfach, denn hierfür müssen Inhalte auf verschiedenen URLs 1 zu 1 übereinstimmen.
Identischer Duplicate Content ist dann gegeben, wenn Website-Betreiber fremde Texte kopieren und auf ihrer eigenen Website unverändert einfügen. Zudem kann identischer Duplicate Content auf der Website aus technischen Aspekten resultieren; auf die technischen Aspekte des Duplicate Contents wird in den nächsten Abschnitten eingegangen.
„Sehr ähnlich“ sind Texte dann, wenn sie umgeschrieben werden, aber dem Ausgangstext stark ähneln, weil einzelne Textbausteine gleichgeblieben sind oder beim Umschreiben kaum neue Wörter verwendet werden.
Letztlich ist die Beurteilung, ob Duplicate Content vorliegt oder nicht, nicht immer einfach. Aus diesem Grund existiert im Internet eine Vielzahl an kostenfreien und kostenpflichtigen Duplicate-Content-Checkern oder Plagiat-Checkern. Drei dieser Programme stellen wir mit Beispiel-Screenshots im Folgenden vor.
Duplicate-Content-Checker: 3 Tools in der Übersicht
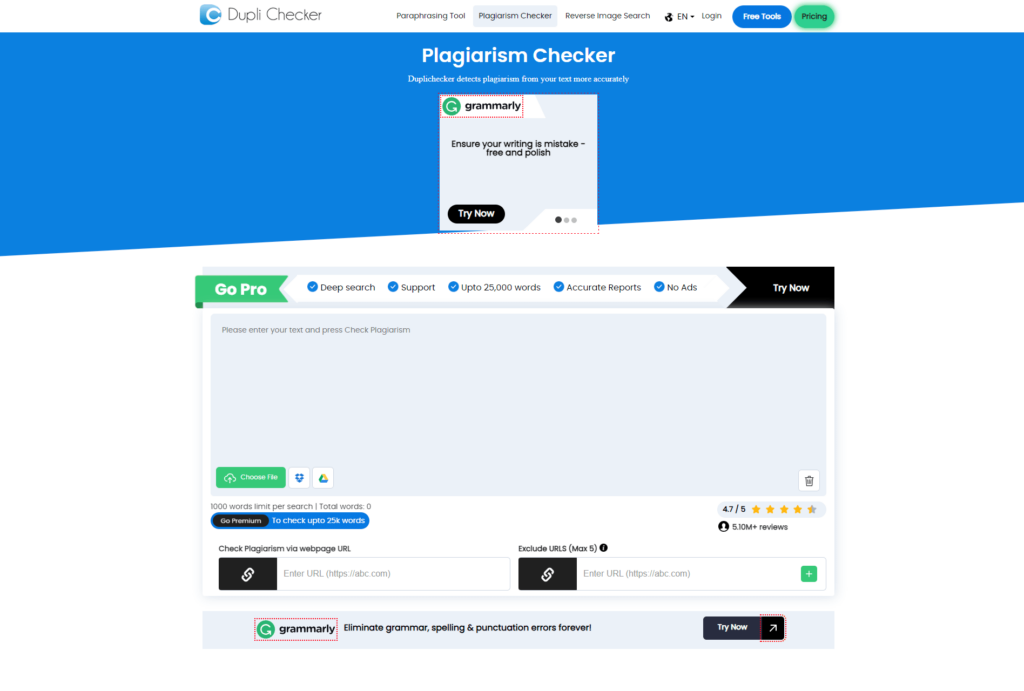
Um Duplicate Content zu vermeiden oder zu erkennen, gibt es Tools. Einige dieser Tools lassen sich nicht nur im Nachhinein, sondern bereits im Verlaufe des Schreibprozesses anwenden, wie z. B. der Duplichecker.
Beim Duplichecker wird der geschriebene Text hineinkopiert und eine Analyse durchgeführt, woraufhin der Anteil der doppelten Inhalte angezeigt wird, die betroffenen Textstellen markiert und die URLs zu den Webseiten mit dem ähnlichen bzw. identischen Inhalt angegeben werden.
Im folgenden Screenshot ist das Textfeld zum Einpflegen des geschriebenen Textes zu sehen. Zudem lässt sich an den weiteren Optionen erkennen, dass es auch möglich ist, Dokumente für den Plagiats-Check hochzuladen.
Ein weiteres Tool für den Duplicate-Content-Check heißt Siteliner. Mithilfe dieses Tools ist es möglich, ganze Websites auf Duplicate Content zu prüfen. Hierzu gibt es eine Maske zur Angabe der Website-URL:

Die von Duplicate Content betroffenen Webseiten können mit einem Klick eingesehen werden. Der schiere Umfang von Siteliner macht das Tool unter Anwendern sehr beliebt. In der kostenpflichtigen Version lassen sich hohe Mengen an Checks durchführen, sodass Siteliner eine gute Option für Online-Marketing-Agenturen, SEO-Experten und weitere Personengruppen ist, die zu beruflichen Zwecken häufige und regelmäßige Duplicate-Content-Checks durchführen.
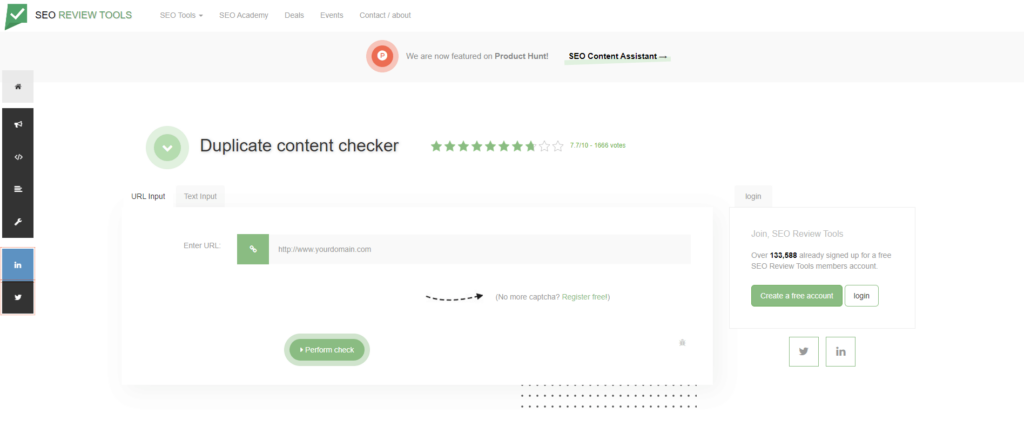
Zuletzt sei mit dem Duplicate Content Checker von SEO-Review-Tools ein Programm vorgestellt, das beide bisher erwähnte Funktionen kombiniert: Das Tool eignet sich sowohl, um bestehende Websites durch die Angabe der URL auf vorhandenen Duplicate Content zu checken, als auch zur Prüfung neu verfasster Texte durch deren Eingabe in ein Textfeld. Bei unserem Check kamen allerdings Zweifel an der Qualität des Tools und dessen Qualität auf.
Letztlich ist keiner der Duplicate-Content-Checker und Plagiats-Checker ein Allheilmittel, das definitiv beim Vermeiden und/oder Erkennen doppelter Inhalte zuverlässig hilft. Trotzdem sollten die Tools genutzt werden, um die Wahrscheinlichkeit für Duplicate Content zu senken.
Alles Weitere zeigt sich im Verlaufe der Suchmaschinenoptimierung: Immer dann, wenn einzelne Seiten abgestraft werden oder nicht so performen, wie sie sollten, sollten Website-Betreiber verstärkt Checks der betroffenen Seiten durchführen, um die Gründe für die Abstrafung bzw. schlechte Performance zu identifizieren und die Seiten bei Bedarf zu optimieren.
Technische und weitere Aspekte von Duplicate Content
Möglich ist, dass auf einer einzigen Website doppelte Inhalte vorkommen. Um eine Abstrafung zu verhindern, können Website-Betreiber Google und anderen Suchmaschinen durch einen Canonical Tag mitteilen, welche Version des Inhalts die bevorzugte ist. In diesem Fall wird durch den Tag auf einer Unterseite der Website auf die andere Unterseite verwiesen:
<link rel=“canonical“ href=“https://www.beispiel.de/beispielseite.htm“/>
Dieser Tag, der u. a. im Head-Element des Quellcodes platziert werden kann, behebt somit das Problem des Duplicate Contents. Es handelt sich hierbei um eine technische Maßnahme.
Eine weitere technische Maßnahme zum korrekten Umgang mit duplizierten Inhalten ist der Noindex-Tag. Wenn beispielsweise Nachrichtenartikel von fremden Websites kopiert werden, handelt es sich um einen Duplicate Content, bei dem ein Canonical Tag zur Behebung des Problems nicht ausreicht.
In diesem Fall sollte die Seite mit doppeltem Inhalt von der Indexierung ausgeschlossen werden. Hierzu bieten die meisten Content-Management-Systeme unter den Seitenoptionen die Möglichkeit, die Seite auf „noindex“ zu setzen.
Ein spezieller Fall von Duplicate Content liegt vor, wenn es durch Domains für verschiedene Länder zu doppelten Inhalten kommt. Hat beispielsweise ein Website-Betreiber jeweils eine separate Domain für andere Länder mit derselben Sprache (z. B. Deutschland, Schweiz oder Österreich), aber auf diesen Domains jeweils dieselben oder sehr ähnliche Texte, so liegt Duplicate Content vor. Hier helfen hreflang-Tags.
Ein Beispiel für einen hreflang-Tag, der im Head-Bereich von Seiten gesetzt wird, lautet wie folgt:
<head>
<meta name=“ title“ content=“Stiefel kaufen – domain.de“ />
<meta name=“description“ content=“Schicke Stiefel kaufen Sie in unserem Shop domain.de: tolle Stiefeltrends – viele Formen, Materialien, Farben – Günstige Stiefel fürs ganze Jahr!™/>
<link rel=“alternate“ hreflang=“de“ href=http://www.domain.de/schuhe/stiefel/>
<link rel=“alternate“ hreflang=“ch“ href=http://www.domain.ch/schuhe/stiefel/>
</head>
Die Endung „ch“ in der vorletzten Code-Zeile zeigt, dass es sich um eine Schweizer Seite handelt.
Neben den genannten Gründen für doppelten Content kann es sein, dass andere Website-Betreiber Content klauen. Der Content-Klau kann Google über eines der Formulare unter diesem Link gemeldet werden. Google wird sich dann darum kümmern, dass nicht der wahre Urheber der Texte, sondern der Webmaster mit den kopierten Inhalten abgestraft wird.
Fazit
Grundsätzlich ist es für die SEO von immenser Bedeutung, Duplicate Content zu vermeiden. In einigen Fällen, wie beispielsweise bei den Produktbeschreibungen in Webshops und in den Footern von Websites, wird Duplicate Content toleriert.
Wer sich nicht sicher ist, ob der Duplicate Content der eigenen Website schadet, sollte Texte ohne doppelte Inhalte veröffentlichen. Abgesehen von der selbstständigen Verfassung von Texten helfen Duplicate-Content-Checker als spezielle Tools bei der Erkennung und Vermeidung von Duplicate Content. Zudem sind technische Maßnahmen hilfreich gegen doppelte Inhalte.



